
You open Chrome, you know the article exists, and you cannot find it. It was open yesterday, maybe the day before. Now it’s buried under 40 tabs, or worse, closed entirely. This is not a memory problem. It’s a retrieval problem. Knowledge workers and researchers lose significant time every week hunting for information they’ve already found once, cycling through bookmarks, browser history, and half-remembered search queries. The good news: information retrieval (IR) has evolved dramatically, and understanding the core methods gives you a real edge in how you access, organize, and act on what you know.
Table of Contents
- What makes an information retrieval method effective?
- Traditional sparse retrieval: Boolean, VSM, and BM25
- Dense neural retrieval and language models
- Hybrid retrieval: Combining sparse and dense for the best of both worlds
- Query expansion: Enhancing retrieval with smarter queries
- Evaluating and benchmarking retrieval methods
- Nuances, edge cases, and choosing the right method
- Stop hunting, start finding with Daysift
- Frequently asked questions
Key Takeaways
| Point | Details |
|---|---|
| Choose hybrid approaches | Hybrid retrieval methods blend precision and recall, outperforming either sparse or dense models alone for complex knowledge work. |
| Benchmark with real data | Rely on metrics like nDCG and MAP along with public datasets to understand practical retrieval performance. |
| Expand queries with care | Use query expansion sparingly to boost recall but monitor for topic drift and over-expansion errors. |
| Prepare for edge cases | Combine multi-stage pipelines and monitoring to handle ambiguous queries, long documents, and out-of-domain topics effectively. |
What makes an information retrieval method effective?
To choose the right method, it helps to know what “effective” really means for information retrieval. Not all retrieval systems are built the same, and the gap between a mediocre and a great one shows up exactly when you need results most.
Effective IR methods are judged on several core criteria:
- Precision: Does the system return only what’s relevant, without flooding you with noise?
- Recall: Does it surface everything relevant, or does it miss key results?
- Speed: How fast does it return results, especially at scale?
- Query handling: Can it manage ambiguous, complex, or multi-part questions?
- Domain robustness: Does it hold up when queries fall outside its training data?
- Tool integration: How easily does it plug into your existing workflow or pipeline?
Empirical benchmarks like nDCG (normalized Discounted Cumulative Gain) and MAP (Mean Average Precision) give researchers a standardized way to compare methods. But real-world performance often diverges from lab scores. As key challenges show, balancing precision and recall, managing latency, and coping with complex queries or edge cases remain the central tensions in IR system design. Knowing these trade-offs upfront helps you pick the right tool for your actual use case, not just the most popular one.
Traditional sparse retrieval: Boolean, VSM, and BM25
With the criteria set, let’s begin with the traditional foundations of information retrieval. Sparse retrieval methods have powered search engines and document systems for decades, and they’re still widely used today for good reason.
Boolean retrieval works on exact keyword matches using AND, OR, and NOT logic. It’s fast and predictable, but rigid. Miss a synonym and you miss the result.
Vector Space Model (VSM) introduced ranking through TF-IDF scoring, measuring how often a term appears in a document relative to how common it is across all documents. This gave search a sense of relevance rather than just presence.
BM25 refined VSM further by adding document length normalization and tunable term frequency saturation. It’s the backbone of systems like Elasticsearch and remains a strong baseline today.
Key strengths of sparse methods:
- Fast query execution, even on massive corpora
- Highly interpretable results (you can trace why a document ranked)
- Strong out-of-domain robustness
- Low compute requirements
The core weakness is the lexical gap: if you search for “automobile” but the document says “car,” sparse methods often miss it. They match tokens, not meaning.
“BM25 and sparse methods dominate on efficiency and out-of-domain robustness but miss subtle semantics.”
For structured, well-defined queries on known terminology, sparse retrieval is hard to beat. For fuzzy, exploratory, or concept-driven searches, it starts to show its limits.
Dense neural retrieval and language models
While sparse methods focus on exact words, neural approaches unlock the power of meaning. Dense retrieval models convert both queries and documents into high-dimensional numerical vectors called embeddings. Similarity is then measured by how close those vectors are in space.
Popular architectures include:
- Bi-encoders (DPR, ColBERT): Encode queries and documents separately, enabling fast approximate nearest-neighbor search
- Cross-encoders: Compare query and document together for higher accuracy, at the cost of speed
- LLM-based retrievers: Use large language models to generate or rerank results based on deep contextual understanding
The payoff is real. Dense neural models unlock semantic search, finding results even when the exact words don’t match. Ask for “that article about SaaS pricing strategies” and a well-tuned dense retriever finds it even if the title says “monetization frameworks for software products.”
But there are trade-offs. Dense models are computationally heavy, require significant infrastructure, and can lose precision on rare or highly specific terms. On the CRUMB benchmark, which tests complex multi-step queries, even the best models score below nDCG@10 of 0.4, revealing real gaps in handling nuanced retrieval tasks.
“Pre-trained transformers unlock semantic search but trade off speed and precision in some circumstances.”
Pro Tip: If you’re evaluating a dense retrieval tool, test it specifically on your domain’s edge cases, not just the demo queries. Generic benchmarks rarely reflect how the model handles your actual vocabulary.
Hybrid retrieval: Combining sparse and dense for the best of both worlds
The next evolution is pairing strengths. Hybrid retrieval fuses BM25 and dense semantic retrieval, typically through techniques like Reciprocal Rank Fusion (RRF) or score normalization. The result is a system that catches both exact keyword matches and conceptual similarities.

| Method | Precision | Recall | Speed | Compute cost |
|---|---|---|---|---|
| BM25 (sparse) | High | Moderate | Very fast | Low |
| Dense neural | Moderate | High | Moderate | High |
| Hybrid (fused) | High | High | Slower | Very high |
The performance gains are significant. Hybrid retrieval improves Precision@10 by 41% and Recall@20 by 67% over BM25 alone, though it comes at a cost: hybrid systems can be up to 800x slower than pure sparse retrieval.
For most knowledge workers, that trade-off is worth it when the query is ambiguous or the document set is large and varied. The practical challenges include:
- Tuning fusion weights between sparse and dense scores
- Managing latency at query time
- Higher infrastructure and compute requirements
- Ensuring consistent performance across different query types
Hybrid is the current gold standard for production retrieval systems that need to handle real-world query diversity.
Query expansion: Enhancing retrieval with smarter queries
Even the best retrieval models miss the mark sometimes. That’s where query expansion earns its keep. Instead of changing the retrieval model, query expansion enriches the query itself before it hits the index.
Common approaches include:
- Pseudo-Relevance Feedback (PRF): Takes the top results from an initial search and mines them for additional terms to add to the query
- Thesaurus-based expansion: Adds synonyms or related terms from a curated vocabulary
- Neural expansion (BERT-QE, ANCE-PRF): Uses language models to generate contextually relevant query variants
- Generative expansion: Prompts an LLM to rewrite or expand the query before retrieval, common in Retrieval-Augmented Generation (RAG) pipelines
Query expansion techniques range from traditional PRF and thesaurus methods to neural and LLM-generated approaches, but over-expansion risks topic drift, where the expanded query pulls in results that are tangentially related but not actually useful.
Pro Tip: In RAG pipelines, generate multiple query variants and retrieve results for each, then fuse the result sets. This dramatically improves recall without the precision loss of naive expansion.
Evaluating and benchmarking retrieval methods
How do you know which retrieval method really delivers? The objective yardstick is benchmarking. Standard metrics give you a consistent way to compare systems across different tasks and domains.
| Metric | What it measures |
|---|---|
| Precision@K | Fraction of top-K results that are relevant |
| Recall@K | Fraction of all relevant docs found in top K |
| MAP | Mean Average Precision across all queries |
| nDCG@K | Ranking quality, weighted by position |
| R-Precision | Precision at the rank equal to total relevant docs |
Two benchmarks matter most right now:
- BEIR: Tests zero-shot retrieval across 18 diverse domains, revealing how well a model generalizes beyond its training data
- CRUMB: Focuses on complex, multi-step queries. Top models on CRUMB score nDCG@10 of just 0.346, showing how much room for improvement remains
Understanding these benchmarks helps you cut through vendor claims. A model that scores well on BEIR may still struggle on your specific domain. Always test on a representative sample of your own queries before committing to a system. For teams building AI-powered retrieval, dataset optimization for AI is a critical upstream step that directly affects downstream retrieval quality.
Nuances, edge cases, and choosing the right method
Even the best systems have weaknesses. Experts navigate these nuances for daily impact, and knowing them in advance saves you from expensive surprises.
Common edge cases to watch for:
- Lexical gap: Sparse methods fail when query and document use different words for the same concept
- Semantic drift: Dense models may match documents that are topically adjacent but not actually relevant
- Long document retrieval: Relevant evidence is scattered across a long document, making partial matches unreliable
- Multi-hop queries: Questions that require connecting information across multiple documents challenge both sparse and dense systems
Hybrid and multi-stage pipelines are the recommended approach for handling these edge cases, combining initial retrieval with reranking and carefully gated query expansion.
The best practice for production systems is a multi-stage pipeline: retrieve broadly with BM25, rerank with a cross-encoder, and apply query expansion only when initial recall is low. Monitor each stage independently so you can diagnose failures without guessing.
Pro Tip: Before choosing a retrieval method, map your most common query types. If most queries are specific and keyword-rich, BM25 may outperform a dense model. If queries are exploratory and concept-driven, go hybrid from the start.
Privacy is also a real consideration. When retrieval tools index your browsing or documents, understanding how that data is stored and processed matters. Reviewing a tool’s privacy and edge case handling before adoption is a step many knowledge workers skip and later regret.
Stop hunting, start finding with Daysift
All of this retrieval theory has a very practical application: the pages and documents you visit every day in your browser. You’ve read the research, you know the trade-offs, and you still spend time hunting for that tab you had open last Tuesday.
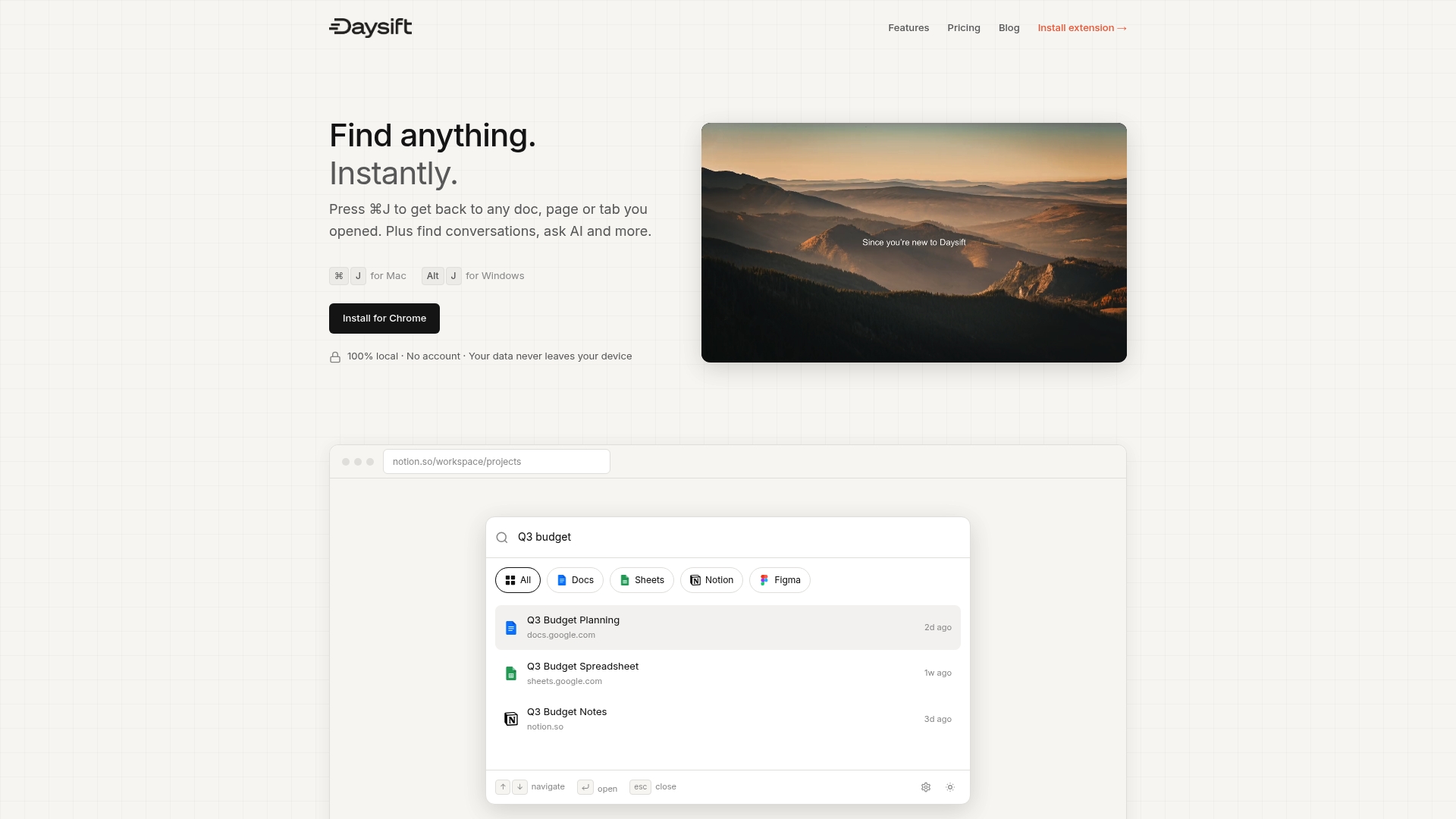
Daysift applies these retrieval principles directly to your browser history, indexing every work-relevant page you visit locally on your machine. One keyboard shortcut (⌘J on Mac, Alt+J on Windows) opens a search palette that supports both keyword and semantic queries. Fuzzy matching handles partial memory. The “Ask AI” feature handles intent-based queries. Your data never leaves your machine. No account, no cloud sync, no tab organization required. It’s the retrieval layer your browser was always missing, starting at free and scaling to $4.99 per month for unlimited AI access.
Frequently asked questions
Which retrieval method is best for everyday knowledge work?
Hybrid retrieval, fusing BM25 with neural reranking, provides the best mix of precision and flexibility for most knowledge workers handling varied, real-world queries.
How does query expansion help when searching large document sets?
Query expansion adds synonyms or contextually relevant terms to improve recall, but it should be applied carefully since over-expansion can pull in off-topic results and reduce precision.
Why do neural models sometimes perform worse on complex queries?
Dense neural retrievers can struggle with multi-step or unusual queries, with top models on CRUMB scoring nDCG@10 of just 0.346, well below what most users expect from a “smart” system.
How can I avoid privacy risks with retrieval tools?
Choose platforms with clear, transparent policies and always review how indexing and retrieval handle your data. Daysift’s privacy policy details exactly what stays local and what, if anything, touches a server.